DB C8 Indexing
Basic Concepts
Indexing mechanisms used to speed up access to desired data. e.g author catalog in library.
Search Key: attribute to set of attributes used to look up records in a file.
index file: consists of records (called index entries) of the form <search-key><pointer>.
Index filesare typically much smaller than the original file.- Two basic kinds of indices:
- Ordered indices:
search keysare stored in sorted order - Hash indices:
search keysare distributed uniformly across “buckets” using ahash function.
- Ordered indices:
Index Evaluation
- Access types supported efficiently.
e.g- Point query: records with a specified value in the attribute.
- Range query: or records with an attribute value falling in a specified range of values.
- Access time
- Insertion time
- Deletion time
- Space overhead
Time and Space efficiency is the most significant indicators in DBS.
Ordered Indices
In an ordered index, index entries are stored sorted on the search key value. e.g, author catalog in library.
Primary and secondary
- Sequentially ordered file: The records in the file (data file) are ordered by a search-key.
- Primary index,主索引 / clustering index,聚集索引: in a sequentially ordered file, the index whose search key specifies the sequential order of the file.
- Index-sequential file, 索引顺序文件 : ordered sequential file with a primary index.
The search key of a primary index is usually but not necessarily the primary key.
-
Secondary index, 辅助索引 / non-clustering index,非聚集索引: an index whose
search keyspecifies an order different from the sequential order of the file.qFrequently, one wants to find all the records whose values in a certain field which is not the search-key of the primary index satisfy some condition.(实际应用中常有多种属性作为查询条件)
ØExample : In the account database stored sequentially by account number, we may want to find all accounts with a specified balance or range of balances. (see next slide)
qWe can have a secondary index with an index record for each search-key value; index record points to a bucket that contains pointers to all the actual records with that one particular search-key value.
辅助索引不能使用稀疏索引,每条记录都必须有指针指向.
但search-key常存在重复项—如700,而index entry不能有重复,否则查找算法复杂化, 为此,使用bucket结构。**
Dense and sparse
-
Dense index, 稠密索引: Index entry appears for every
search-key valuein the file.For tuples with
search-key value, not all tuples will be indexed.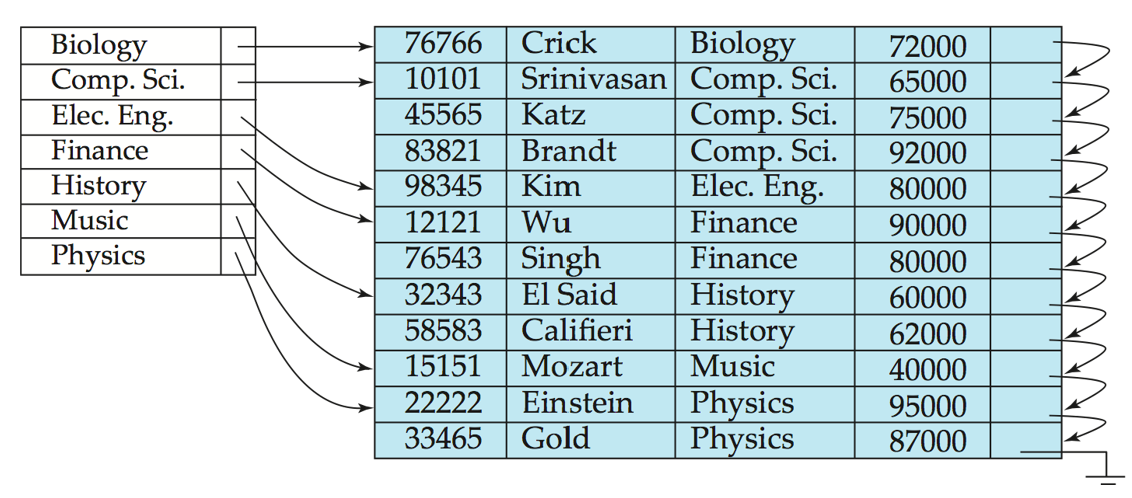
-
Sparse index, 稀疏索引: contains index entries for only some
search-key values. ( Usually, one block of data gives an index entry, a block contains a number of ordered data records)Sparse indexis applicable only when data file records are sequentially ordered on search-key!To locate a record with
search-key valueK :- Find index record with largest
search-key value< K - Search file sequentially starting at the record to which the index entry points.
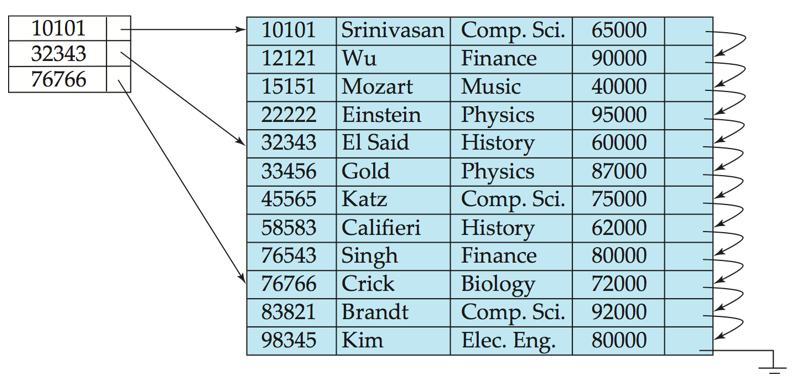
- Find index record with largest
Comparison of dense and sparse
Sparseconsumes less space and less maintenance overhead for insertions and deletions.denseis generally quicker for locating records.denseis applicable for non-sequentially files.
Good tradeoff
Sparse index with an index entry for every block in file, corresponding to least search-key value in the block.
Multilevel Index
If primary index is too big to fit in memory, access becomes expensive.
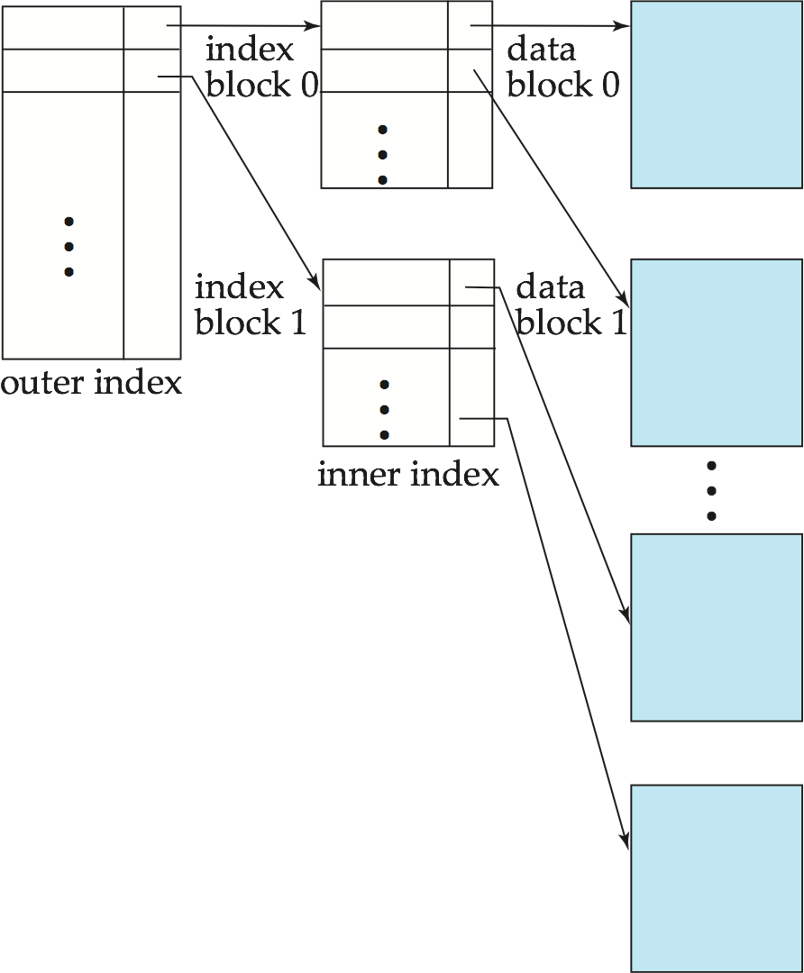
qTo reduce number of disk accesses to index records, treat primary index kept on disk as a sequential file and construct a sparse index on it. (把内层索引文件看作顺序数据文件一样,在其上建立外层的稀疏索引)
ØOuter index – a sparse index of primary index
ØInner index – the primary index file
qIf even outer index is too large to fit in main memory, yet another level of index can be created, and so on.(可以推广到任意多层索引)
qIndices at all levels must be updated on insertion or deletion from the file.
Update
Deletion
- The system finds the record in the data file, then deletes the record.
- updates index file: (for single-level index deletion).
Dense indices
The deleted record was:
-
the only record with its particular
search-key value: (单记录, search-key唯一性)delete corresponding index entry from index file.
-
Not the only record:
secondary index: multi pointers to all records with the samesearch-key value:
delete the pointer to the deleted record from the index entry.
-
primary index:- deleted record was the first record: change the pointer to the next record.
- Otherwise: do nothing.
Sparse
The search-key values of the deleted record:
- does not appear in the index: do nothing.
- Otherwise:
- if an index entry for the search key exists in the index file, it is deleted by replacing the entry with the next search-key value in the data file (in search-key order).
- If the next search-key value already has an index entry, the index entry is deleted instead of being replaced.
Insertion
- Perform a lookup using the
search-key valueappearing in the record to be inserted. - Insert the record.
- Update the index file.