ML C1,2 绪论,基本术语与模型评估
Course Info
Grading Policy
- 平时 60: 15 * 1 签到 / 10 * 2 纸质作业 / 25 编程作业
- kaggle -
- 期末 40:最后两节课随堂考试
Textbook
- 机器学习 - 周志华
- lecture notes
机器学习
-
机器学习:以数据为经验的载体,利用经验不断改善性能的(计算机)系统 / 程序 / 算法。
人工智能的核心研究领域 / 实现智能化的关键
智能数据分析
-
[Mitchell, 1997]更形式化的定义:
假设用 来评估计算机程序在某任务类 上的性能。
若一个程序通过利用经验 在 中任务上获得了性能改善,则说关于 和 ,该程序对 进行了学习。
机器学习与 ··· ···
数据挖掘
- 数据挖掘, data mining:从海量的数据中挖掘出一些不平凡的知识。
- ML 和 DM 都包括数据分析。同时 ML, DBMS, 统计学是数据挖掘的关键支撑技术,ML更底层。
大数据研究
前沿
JMLR / TPAMI / NeurIPS / ICML / AAAI / KDD
From tutorial
基本术语与概念
数据, Data
- 特征 / 属性
- 属性值:特征的离散 / 连续取值
- 样本维度, Dimensionality:特征个数
- 属性空间 / 特征空间 / 输⼊空间: 特征张成的空间
- 标记空间 / 输出空间:标记张成的空间
- 示例, Instance / 样本, Sample:⼀个对象的 input
示例不含标记 - 样例, Example:示例 + 标记
- 训练集 :⼀组训练样例
- 测试集:⼀组测试样例
任务
- 根据*
label的取值*情况- 离散值 - 分类任务:
- 二分类:正类 positive,反类 negative
- 多分类:如(冬瓜,南瓜,西瓜)
- 连续值 - 回归任务:如 瓜的成熟度
- 空 值 - 聚类任务:对
示例进行自动分组
- 离散值 - 分类任务:
- 根据*
label的完整*情况- (有)监督学习:所有
示例都有标记 | 分类、回归 - 无监督学习:所有
示例都没有标记 | 聚类 - 半监督学习:少量
示例有标记,大量示例没标记 - 噪音标记学习:
标记不完全准确
- (有)监督学习:所有
目标
泛化 generalization 能力 : base on 历史数据 / ML 根本目的
I.I.D 假设: 历史和未来来自相同分布。
我们希望
训练集能很好地反映出样本空间的特性,否则就很难期望在训练集上学得的模型能在整个样本空间上都工作得很好。通常假设样本空间中全体样本服从一个未知分布 distribution,且我们获得的每个样本都是*独立地*从这个分布上采样获得的。即 独立同分布,independent and identically distributed。
概念学习
-
归纳学习, inductive learning:归纳 induction 是从特殊到一般的泛化过程,从具体的事实归结出一般性规律。
-
广义:从样例中学习
-
狭义:从训练数据中学得 概念, concept 可解释的,链条可信的
然而在现实生活中只能做到 “黑盒” 模型
-
-
假设空间:所有假设, hypothesis组成的空间。
-
版本空间, version space:基于有限
样本训练集的多个一致的假设的集合。 -
归纳偏好, inductive bias:尽管有多个一致的假设,模型最终只选择一个假设,这个假设具有其归纳偏好。尽可能特殊 / 尽可能一般?
Thm. 一个算法 如果在某些问题上比另一个算法 好,必然存在另一些问题, 比 好。
假设样本空间 和假设空间 都是离散的,令
- - 算法 基于训练数据 产生假设 的概率
- - 希望学习的真实目标函数.
- - 训练集外误差,即 在训练集之外的所有样本上的误差
模型评估
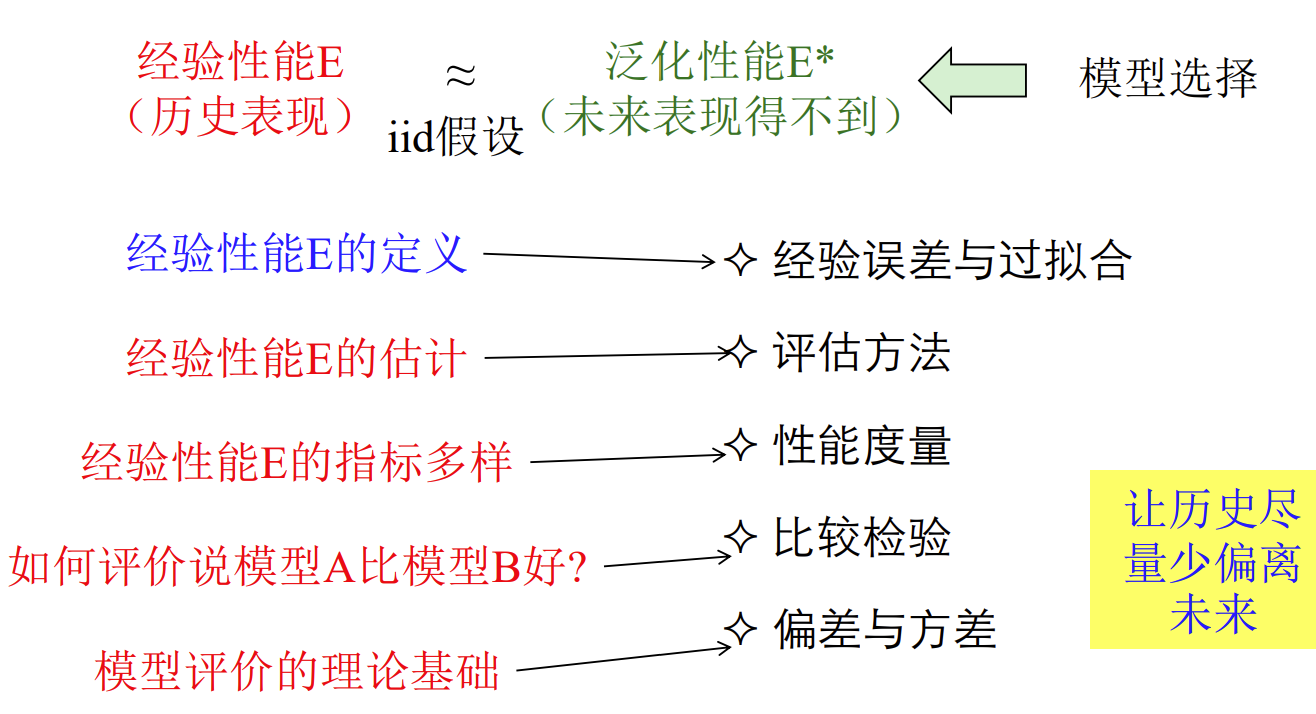
经验误差与过拟合
在 i.i.d 假设下,优化目标 泛化性能 可通过 经验性能 评估。
-
错误率, error rate:
-
误差, error:真实输出与预测输出之间的差异
- 训练 / 经验误差:训练集误差
- 测试误差: 测试集误差
过拟合 欠拟合 训练样本的较为特异的特点当作所有样本的一般性质 没学到训练样本的一般性质 优化目标加入正则项
early stopping拓展分支 or 增加epoch
评估方法
留出法, hold-out
接将数据集。划分为两个互斥的集合,其中一个 集合作为训练集S ,另一个作为测试集T
,训练/测试集的划分要尽可能保持数据分布的一致性,避免 因数据划分过程引入额外的偏差而对最终结果产生影响,例如在分类任务中 至少要保持样本的类别比例相似.如果从采样(sampling)的角度来看待数据 集的划分过程,则保留类别比例的采样方式通常称为分层采样
交叉验证法, cross validation
留一法(Leave-One-Out,简 称 L O O )
“自助法”(bootstrapping)
性能度量
-
均方误差
-
分类错误率
-
分类精度
-
混淆矩阵
recall见
• ⽐较检验 • 偏差与⽅差